
Highlights §
- Today, we are excited to announce the private beta for Cohere Compass, our new foundation embedding model that allows indexing and searching on multi-aspect data. (View Highlight)
- Multi-aspect data can best be explained as data containing multiple concepts and relationships. This is common within enterprise data — emails, invoices, CVs, support tickets, log messages, and tabular data all contain substantial content with contextual relationships. Retrieval of this data is an ongoing challenge because 1) enterprise data can contain many concepts, and 2) the relationship between concepts needs to be understood. (View Highlight)
- To address this, developers would need to create a classification layer to identify and match distinct aspects from a query to specific metadata fields in the documents. This is quite difficult to build and host, and would be constrained to the values only understood by the classifiers. (View Highlight)
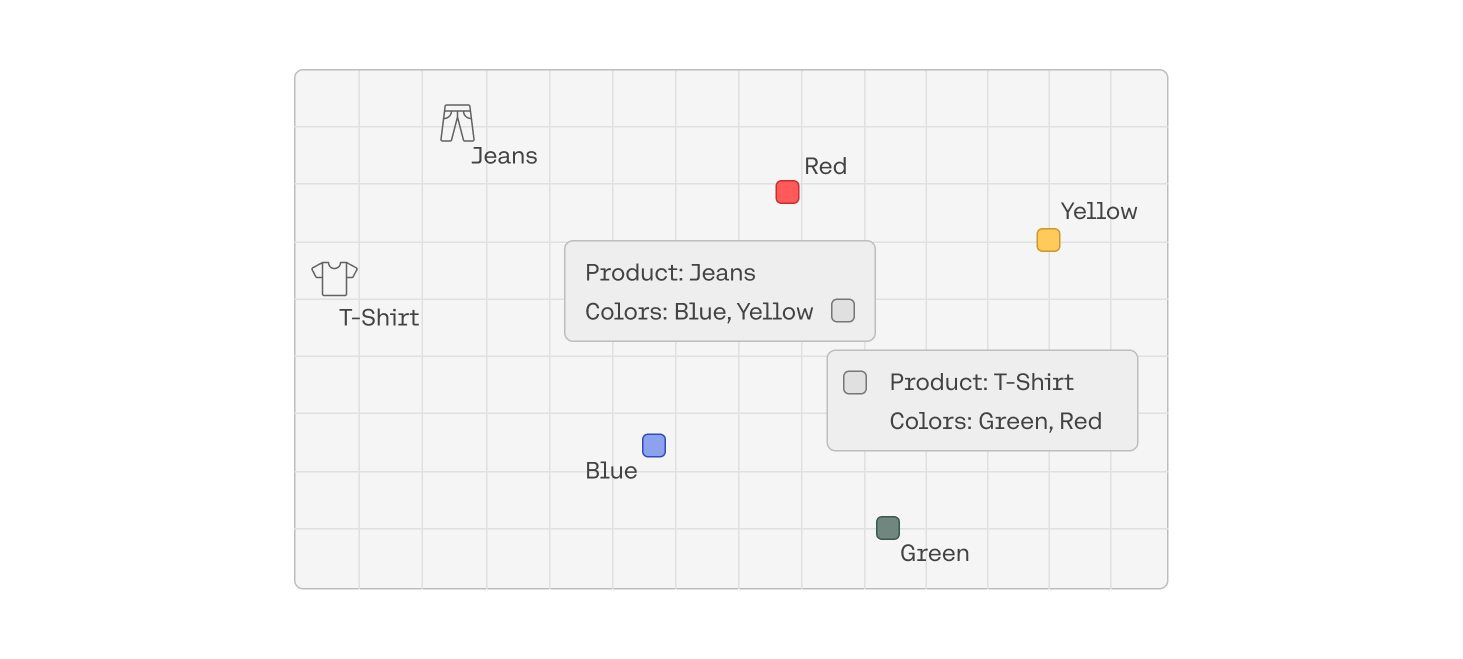
- Also, existing embedding approaches aren’t able to address the problem. The best existing embedding models, such as Cohere Embed v3, convert documents into a single vector within a semantic vector space: (View Highlight)
 (View Highlight)
(View Highlight)- While this works well when your document is focused on a single attribute, these embedding models start to struggle once several aspects and concepts are present in the data. In the above example, we see that the jeans that are available in blue and yellow have a similar embedding as the T-shirt that is available in green and red. These embeddings are placed between each color pairing, losing any semantic tie to the specific colors. Now if searching for a “red T-shirt”, we are unlikely to return similar T-shirt products. In fact, the top result for “red t-shirt” in our limited example here would be the “blue and yellow jeans”. (View Highlight)
- Cohere Compass is designed to address multi-aspect data. With Compass, data can be passed as JSON documents to the Compass embedding model, which transforms it into a special format and stores its representation in vector databases. The embeddings output can be stored in any vector database. (View Highlight)
- In a traditional RAG pipeline, we would index an email with a PDF attachment independently. We would convert the PDF to text, and then chunk the text on paragraph or page level, and index the chunks individually in our vector database. See the diagram below for a visual explanation of this process. (View Highlight)
- The challenge with this approach is that we lose the contextual information that the PDF was sent via email and was sent by a specific person at a specific time, with potentially additional context as part of the email subject or body. (View Highlight)
- With Compass, the parsing SDK helps with all these details. Converting your data to JSON and then into an embedding output is a two-stage process:
- The Compass SDK parses the email and all the attachments into a single JSON.
- The JSON is passed to the Compass embedding model resulting in an embedding output that can be stored in any vector database.
The metadata and text are stored, along with multi-aspect representations capturing the relationship between concepts present in the multi-aspect data. (View Highlight)
- Below is an example where we’re searching for GitHub issues that contain bugs, feature requests, pull requests, investigations, and questions. The query is “first cohere embeddings PR”, and it contains a time aspect (first), a semantic subject (cohere embeddings), and then the type (PR -> Pull Request). (View Highlight)
- On the right, we see that the dense embedding models do not fulfill the request for the “first Cohere embeddings PR.” In the first search result, it gets the PR type right but wrong subject and wrong time. The second search result gets the subject right but not the time or type. And the third result returns the wrong subject, wrong type, and wrong time. (View Highlight)