Highlights §
- These days it feels like every company is abandoning its monolith to move fast and break things. Microservices are an architectural pattern that changes how applications are structured by decomposing them into a collection of loosely connected services that communicate through lightweight protocols. A key objective of this approach is to enable the development and deployment of services by individual teams, free from dependencies on others.
By minimizing interdependencies within the code base, developers can evolve their services with minimal constraints. As a result, organizations scale easily, integrate with off-the-shelf tooling as and when it’s needed, and organize their engineering teams around service ownership. (View Highlight)
- Zhamak Dehghani, the pioneer behind Data Mesh (and also a Thoughtworker) released her book on the data equivalent to microservices - the Data Mesh.
 (View Highlight)
(View Highlight)
- The world of data always seems to be playing catch-up to software and finally adopting microservice-oriented language is no different (View Highlight)
- I am going to take a contrarian approach and argue that data is NOT like a microservice. While I think a data mesh is one way of dealing with the organizational complexity that comes with handling the challenges posed to data teams, my perspective is that data requires a related, but uniquely different paradigm. My thesis is based on three core arguments:
- Data teams require a source of truth, which microservices cannot provide without an overhaul of the software engineering discipline
- We can’t know in advance when data will become valuable, which makes up-front ownership of data microservices overly restrictive
- The data development lifecycle is different from the software engineering development lifecycle, and microservices are a poor fit to facilitate the needs of data teams (View Highlight)
- Microservice-based approaches do not solve the most important problem in data - A missing source of truth. (View Highlight)
- While I touched upon this in my last article, it bears repeating here: The motivations of a software engineering team are inherently different than a data team. An engineering team makes architectural design choices to facilitate speed, separation of concerns, and flexibility. The reason for this is clear- engineers are expected to ship features quickly. (View Highlight)
- The purpose of a microservice is to power an aspect of some customer experience. Its primary function is operational. The purpose of data is decision-making. Its primary function is TRUTH. How that truth is used can be operational (like an ML model) or analytical (answering some interesting question). (View Highlight)
- Data developers struggle because the data they have taken dependencies on has no ownership, the underlying meaning is not clear, and when something changes from a source system very few people know why and what they should expect the new ‘truth’ to be as a result. In data, our largest problems are rooted in a lack of trust.
In my opinion, a source of truth is an explicitly owned, well-managed, semantically valid data asset that represents an accurate representation of real-world entities or events reflected in code. (View Highlight)
- In the traditional on-premise Data Warehouse, an experienced data architect was responsible for defining the source of truth in a monolithic environment. While slow and somewhat clunky to use, it fulfilled the primary role of a data ecosystem. Smart, hard-working data professionals maintained an integration layer to ensure downstream consumers could reliably use a set of vetted, trustworthy data sets. (View Highlight)
- In the world of microservices, however, there is no truth with a capital ‘T.’ Each team is independently responsible for managing their data product which can and often will contain duplicative information. There is nothing that prevents the same data from being defined by multiple microservices in different ways, from being called different names, or from being changed at any time for any reason without the downstream consumers being told about it. (View Highlight)
- For instance, at Convoy, a metric called
shipment_margin was calculated as the revenue we made servicing a load minus the costs of servicing the load. Many teams had a separate view of which costs were germane to their particular revenue stream. These teams would add dimensions, stack CASE statements on top of their SQL queries like Jenga blocks, rename columns, and ultimately push data to new models where it was reused later, often with vastly different assumptions.
As a data consumer, this made life miserable. It was impossible to tell which data could be depended on, which was production-grade and which was experimental, how columns or tables with similar names differed from each other without exploring the underlying query and resulted in the analyst spending weeks contacting upstream developers to understand what the incoming data meant and how to use it in order to recreate the wheel all over again.
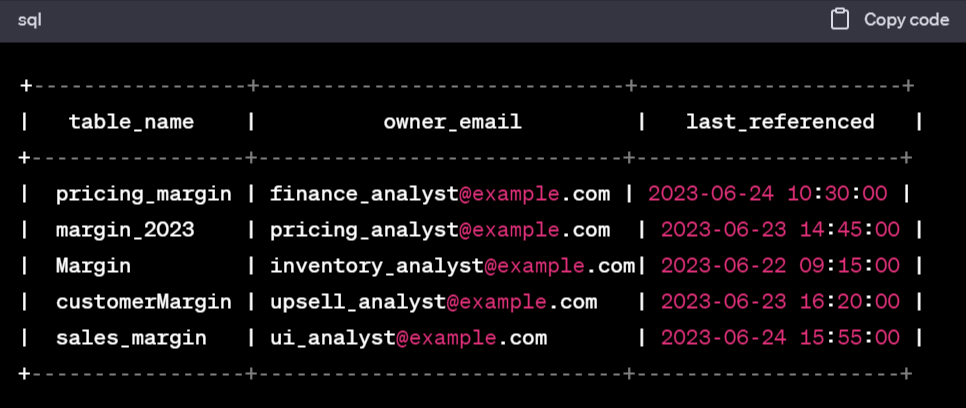 Which one of these should I use if I want margin? (View Highlight)
Which one of these should I use if I want margin? (View Highlight)
- Not only does this model make data more difficult to access and trust, but it substantially increases cost as well. Cloud analytical database pricing is based on the amount of compute resources utilized during query execution. As complex queries consume more resources, they can increase the cost per query and the overall billing. Without any form of centralization, each team is left to decide how to best compute the same set of metrics. While this might be trivial for any individual analyst, it becomes incredibly cost prohibitive when repeated thousands of times across the business against massive datasets. (View Highlight)
- Bottom line: The most foundational principle of data is truth. Depending on the use case, the amount of ROI we gain from the data being more accurate can be small (ad hoc reporting) or large (audited accounting pipelines). Teams need the flexibility to evolve a directional dataset into one that is more trustworthy as the need arises. In the world of microservices, we simply give up on the truth altogether and accept that each team will ultimately operate in a silo. (View Highlight)
- This brings us to the next major problem with the microservices-oriented approach: The vast majority of data in a data lake is not actually that useful. (View Highlight)
- The fact a data asset’s value changes over time is very different philosophically from the role of a microservice. A microservice architecture is purpose-built for a function today. No one builds a microservice because it one day might have value. If a potential future was your justification for a new application, every engineer would tell you the same thing: (View Highlight)
- On average, between 60% and 73% of all data within an enterprise goes unused for analytics.” That means up to 3/4 of all the data in a lake isn’t leveraged at all! (View Highlight)
- A majority of companies have hundreds if not thousands of scattered dashboards that were leveraged at one point but no longer. There is so much clutter it becomes difficult to know what questions have already been answered or not. Because moving to a microservice-oriented approach to data doesn’t solve this problem (in fact, it makes it worse given point one), duplication will continue on an exponential spiral with the now-added cost that engineering teams are expected to maintain these useless artifacts upstream. This is not only unscalable from a data management perspective, but it would also be disastrous for engineering velocity. (View Highlight)
- The bottom line: The vast majority of data in a data lake or modern “warehouse” is not useful. Placing restrictions to manage data before it becomes useful is overly restrictive for data producers. Producers should only be required to take ownership once a data asset has been determined to have value and not before. Ownership should begin with ensuring the existing pipelines don’t break through simple data contracts but can extend to more complex contracts with business-driven PII or data security constraints. Ownership must be incremental based on the use case. (View Highlight)
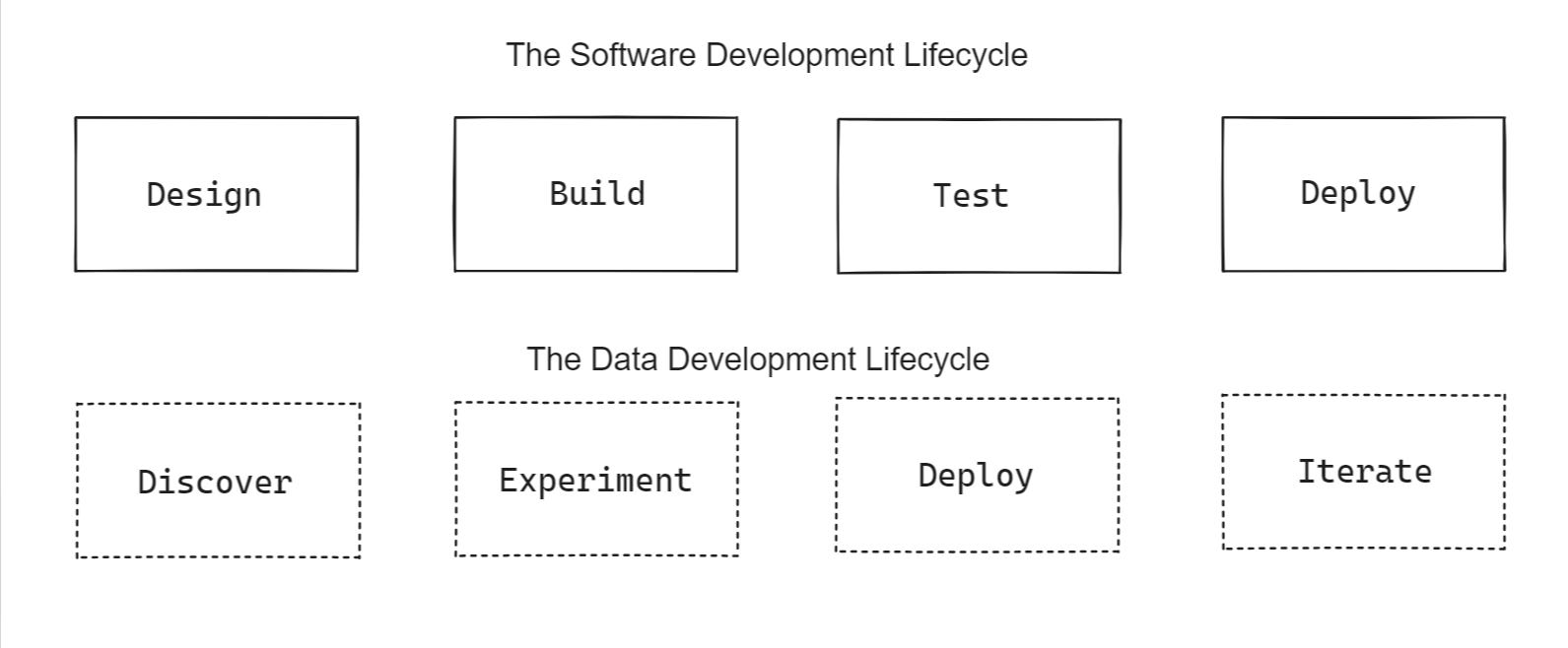
- Now let’s examine the Lifecycle of Data Development.
- Ask an interesting question about the business
- Understand the data that already exists, where it comes from, and what it means
- Construct a query (code) that answers the question
- Decide if the answer to the question has operational value
- If yes, deploy the query into a production environment
- Decide if the query requires data quality and governance
- If yes, build a robust data model and data quality checks/alerting throughout the pipeline (upstream ownership is required here)
- As new data becomes available or changes, continuously evaluate and reconstruct the query accordingly
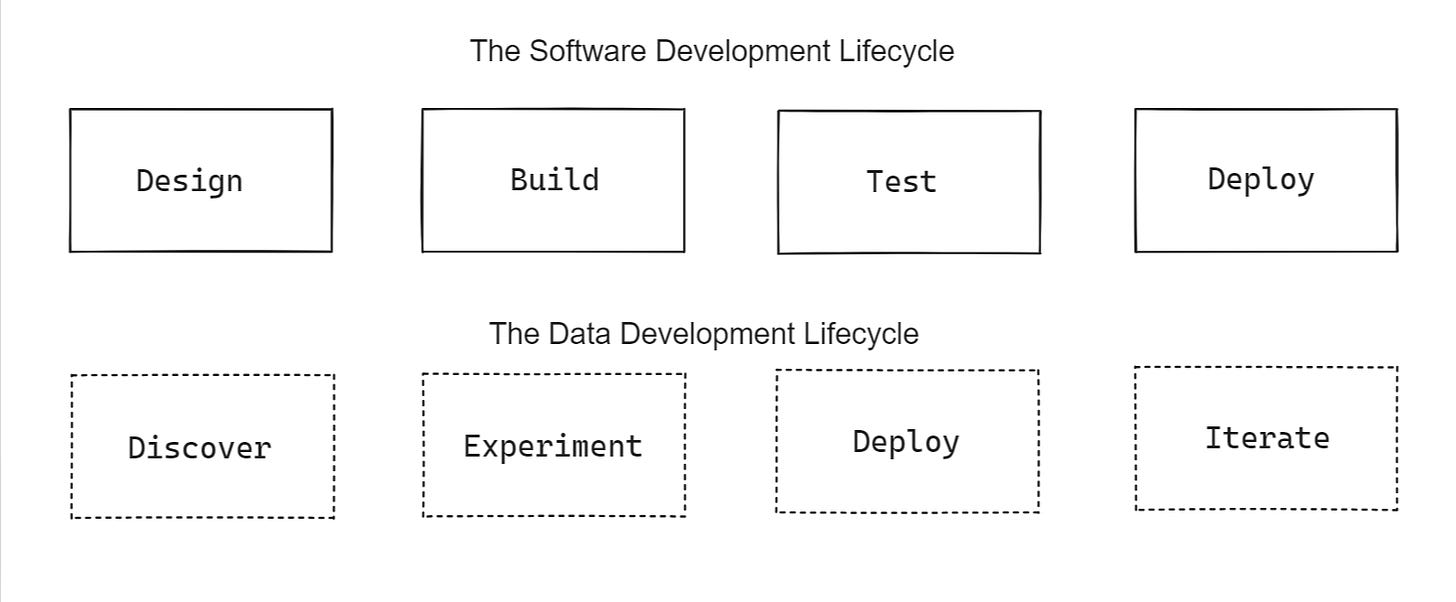 As you might intuit, the two lifecycles are very different. While the SDL produces fit-for-purpose software, data engineering is all about discovering and reusing what already exists for a new use case. Data is always changing as we acquire more of it! It is expected that data implementations will evolve over time, sometimes radically. Thus, it is not self-sufficient and downstream teams are tightly coupled to upstream producers.
The bottom line: As mentioned at the beginning of the post, Microservices are designed to allow flexibility, speed, independence, and stability. However, the Data Development Lifecycle requires discovery, reuse, tight coupling, and constant change/evolution. Microservices and Data Development are incompatible frameworks**.** Applying
As you might intuit, the two lifecycles are very different. While the SDL produces fit-for-purpose software, data engineering is all about discovering and reusing what already exists for a new use case. Data is always changing as we acquire more of it! It is expected that data implementations will evolve over time, sometimes radically. Thus, it is not self-sufficient and downstream teams are tightly coupled to upstream producers.
The bottom line: As mentioned at the beginning of the post, Microservices are designed to allow flexibility, speed, independence, and stability. However, the Data Development Lifecycle requires discovery, reuse, tight coupling, and constant change/evolution. Microservices and Data Development are incompatible frameworks**.** Applying
 Square Pegs in Round Holes
Data has some differences from software that generally make microservices untenable to fulfill the needs of both analytics and data products.
Square Pegs in Round Holes
Data has some differences from software that generally make microservices untenable to fulfill the needs of both analytics and data products.
- Data requires a source of truth: Microservices are inherently siloed. Each team has its own source of truth which creates infinite fragmentation.
- Not all data is equally valuable: There is a big cost to treating all data as a microservice - engineers must take ownership of data that doesn’t even have a use case, or might lose its value over time. This runs counter to how the usefulness of data assets ebb and flow as use cases change.
- The Data Development Lifecycle is different from Software: Data teams care a lot about discovery and repurposing data for new use cases, which ultimately results in very tight upstream dependencies. Microservices are built to eliminate dependencies - the opposite of this workflow.
So what should we be doing, if not microservices? The old-school database management approach doesn’t work for federated teams shipping products quickly, therefore the solution must be compatible with microservice while still enabling a proper data dev workflow. It’s essential to begin from first principles and map out what should be true in the ideal environment, then work backward to the technology and organizational patterns that can enable that approach:
• Data teams should have the freedom to iterate and experiment on raw data from production with minimal restrictions
• Engineering teams should not be required to take ownership of pipelines purely for the purpose of prototyping/experimentation
• Once a strong use case has been established downstream, data consumers should be able to ‘promote’ data assets to a higher quality
• The promotion that occurs should establish the data asset as a source of truth. Any future promotions should modify the source of truth asset instead of creating multiple versions
• Source of truth assets should be forked from production-grade pipelines to replace the corresponding raw data in prototyping environments
• Data producers should be aware of changes to their dependencies when these promotions occur. They should be aware of the impact backward incompatible changes might have on data dependents as well
• Data producers should have a vehicle for managing change communication as their services evolve over time, such as managing release notes and announcing deprecated fields
• If a data asset no longer becomes useful to consumers, data producers should not be required to support it as a product
• Data Governance should be added incrementally when and where it is needed based on the use cases, but not before.
My opinion is that microservices and Data Mesh is probably the right long-term solution, but like AGILE before it, represents an idealized late-stage organizational model. The actual system most companies use does not follow the AGILE manifesto to the letter but instead implements technology that makes it unbelievably easy to ship code iteratively, of which microservices are one example.
In the same way, it should be unbelievably easy for data producers and consumers to collaborate across all stages of the data development lifecycle, ultimately culminating in data products supported with quality and data contracts when it is needed.
In my next article, I’ll be diving more into what an architecture that facilitates the Data Developer Lifecycle in federated ecosystems looks like, and how it interfaces with data contracts, observability, data catalogs, and iterative governance.
 An example of a data contract-oriented architecture
Microservices were designed for software developers. Software is not data. If businesses continue to apply square pegs to round holes, the usefulness of their initiatives in Analytics or AI will ultimately never pan out the way they want. Data Engineers must be self-advocates. Help CTOs understand how the data development roles differ and where they are similar. It will be 100x easier to solve the problems you must if you can.
Thank you so much for taking the time to read this write-up and please subscribe to the newsletter if you enjoyed it! Also, every share helps me grow (and gives me the motivation to keep writing pieces like this) so that would be incredibly appreciated as well. Follow me on LinkedIn and now Twitter for more posts on data engineering, data ownership, and data quality.
Good luck!
-Chad
Share
An example of a data contract-oriented architecture
Microservices were designed for software developers. Software is not data. If businesses continue to apply square pegs to round holes, the usefulness of their initiatives in Analytics or AI will ultimately never pan out the way they want. Data Engineers must be self-advocates. Help CTOs understand how the data development roles differ and where they are similar. It will be 100x easier to solve the problems you must if you can.
Thank you so much for taking the time to read this write-up and please subscribe to the newsletter if you enjoyed it! Also, every share helps me grow (and gives me the motivation to keep writing pieces like this) so that would be incredibly appreciated as well. Follow me on LinkedIn and now Twitter for more posts on data engineering, data ownership, and data quality.
Good luck!
-Chad
Share


- Now let’s examine the Lifecycle of Data Development.
- Ask an interesting question about the business
- Understand the data that already exists, where it comes from, and what it means
- Construct a query (code) that answers the question
- Decide if the answer to the question has operational value
- If yes, deploy the query into a production environment
- Decide if the query requires data quality and governance
- If yes, build a robust data model and data quality checks/alerting throughout the pipeline (upstream ownership is required here)
- As new data becomes available or changes, continuously evaluate and reconstruct the query accordingly
As you might intuit, the two lifecycles are very different. While the SDL produces fit-for-purpose software, data engineering is all about discovering and reusing what already exists for a new use case. Data is always changing as we acquire more of it! It is expected that data implementations will evolve over time, sometimes radically. Thus, it is not self-sufficient and downstream teams are tightly coupled to upstream producers.
The bottom line: As mentioned at the beginning of the post, Microservices are designed to allow flexibility, speed, independence, and stability. However, the Data Development Lifecycle requires discovery, reuse, tight coupling, and constant change/evolution. Microservices and Data Development are incompatible frameworks**.** Applying
Square Pegs in Round Holes
Data has some differences from software that generally make microservices untenable to fulfill the needs of both analytics and data products.
- Data requires a source of truth: Microservices are inherently siloed. Each team has its own source of truth which creates infinite fragmentation.
- Not all data is equally valuable: There is a big cost to treating all data as a microservice - engineers must take ownership of data that doesn’t even have a use case, or might lose its value over time. This runs counter to how the usefulness of data assets ebb and flow as use cases change.
- The Data Development Lifecycle is different from Software: Data teams care a lot about discovery and repurposing data for new use cases, which ultimately results in very tight upstream dependencies. Microservices are built to eliminate dependencies - the opposite of this workflow.
So what should we be doing, if not microservices? The old-school database management approach doesn’t work for federated teams shipping products quickly, therefore the solution must be compatible with microservice while still enabling a proper data dev workflow. It’s essential to begin from first principles and map out what should be true in the ideal environment, then work backward to the technology and organizational patterns that can enable that approach:
• Data teams should have the freedom to iterate and experiment on raw data from production with minimal restrictions
• Engineering teams should not be required to take ownership of pipelines purely for the purpose of prototyping/experimentation
• Once a strong use case has been established downstream, data consumers should be able to ‘promote’ data assets to a higher quality
• The promotion that occurs should establish the data asset as a source of truth. Any future promotions should modify the source of truth asset instead of creating multiple versions
• Source of truth assets should be forked from production-grade pipelines to replace the corresponding raw data in prototyping environments
• Data producers should be aware of changes to their dependencies when these promotions occur. They should be aware of the impact backward incompatible changes might have on data dependents as well
• Data producers should have a vehicle for managing change communication as their services evolve over time, such as managing release notes and announcing deprecated fields
• If a data asset no longer becomes useful to consumers, data producers should not be required to support it as a product
• Data Governance should be added incrementally when and where it is needed based on the use cases, but not before.
My opinion is that microservices and Data Mesh is probably the right long-term solution, but like AGILE before it, represents an idealized late-stage organizational model. The actual system most companies use does not follow the AGILE manifesto to the letter but instead implements technology that makes it unbelievably easy to ship code iteratively, of which microservices are one example.
In the same way, it should be unbelievably easy for data producers and consumers to collaborate across all stages of the data development lifecycle, ultimately culminating in data products supported with quality and data contracts when it is needed.
In my next article, I’ll be diving more into what an architecture that facilitates the Data Developer Lifecycle in federated ecosystems looks like, and how it interfaces with data contracts, observability, data catalogs, and iterative governance.
An example of a data contract-oriented architecture
Microservices were designed for software developers. Software is not data. If businesses continue to apply square pegs to round holes, the usefulness of their initiatives in Analytics or AI will ultimately never pan out the way they want. Data Engineers must be self-advocates. Help CTOs understand how the data development roles differ and where they are similar. It will be 100x easier to solve the problems you must if you can.
Thank you so much for taking the time to read this write-up and please subscribe to the newsletter if you enjoyed it! Also, every share helps me grow (and gives me the motivation to keep writing pieces like this) so that would be incredibly appreciated as well. Follow me on LinkedIn and now Twitter for more posts on data engineering, data ownership, and data quality.
Good luck!
-Chad
Share
- Now let’s examine the Lifecycle of Data Development.
- Ask an interesting question about the business
- Understand the data that already exists, where it comes from, and what it means
- Construct a query (code) that answers the question
- Decide if the answer to the question has operational value
- If yes, deploy the query into a production environment
- Decide if the query requires data quality and governance
- If yes, build a robust data model and data quality checks/alerting throughout the pipeline (upstream ownership is required here)
- As new data becomes available or changes, continuously evaluate and reconstruct the query accordingly (View Highlight)
-
As you might intuit, the two lifecycles are very different. While the SDL produces fit-for-purpose software, data engineering is all about discovering and reusing what already exists for a new use case. Data is always changing as we acquire more of it! It is expected that data implementations will evolve over time, sometimes radically. Thus, it is not self-sufficient and downstream teams are tightly coupled to upstream producers. (View Highlight)
- Microservices are designed to allow flexibility, speed, independence, and stability. However, the Data Development Lifecycle requires discovery, reuse, tight coupling, and constant change/evolution. Microservices and Data Development are incompatible frameworks**.** Applying (View Highlight)
- Data has some differences from software that generally make microservices untenable to fulfill the needs of both analytics and data products.
- Data requires a source of truth: Microservices are inherently siloed. Each team has its own source of truth which creates infinite fragmentation.
- Not all data is equally valuable: There is a big cost to treating all data as a microservice - engineers must take ownership of data that doesn’t even have a use case, or might lose its value over time. This runs counter to how the usefulness of data assets ebb and flow as use cases change.
- The Data Development Lifecycle is different from Software: Data teams care a lot about discovery and repurposing data for new use cases, which ultimately results in very tight upstream dependencies. Microservices are built to eliminate dependencies - the opposite of this workflow (View Highlight)
- It’s essential to begin from first principles and map out what should be true in the ideal environment, then work backward to the technology and organizational patterns that can enable that approach:
• Data teams should have the freedom to iterate and experiment on raw data from production with minimal restrictions
• Engineering teams should not be required to take ownership of pipelines purely for the purpose of prototyping/experimentation
• Once a strong use case has been established downstream, data consumers should be able to ‘promote’ data assets to a higher quality
• The promotion that occurs should establish the data asset as a source of truth. Any future promotions should modify the source of truth asset instead of creating multiple versions
• Source of truth assets should be forked from production-grade pipelines to replace the corresponding raw data in prototyping environments
• Data producers should be aware of changes to their dependencies when these promotions occur. They should be aware of the impact backward incompatible changes might have on data dependents as well
• Data producers should have a vehicle for managing change communication as their services evolve over time, such as managing release notes and announcing deprecated fields
• If a data asset no longer becomes useful to consumers, data producers should not be required to support it as a product
• Data Governance should be added incrementally when and where it is needed based on the use cases, but not before. (View Highlight)