Google “We Have No Moat, and Neither Does OpenAI” §
Highlights §
- But the uncomfortable truth is, we aren’t positioned to win this arms race and neither is OpenAI (View Highlight)
- I’m talking, of course, about open source. Plainly put, they are lapping us. Things we consider “major open problems” are solved and in people’s hands today. (View Highlight)
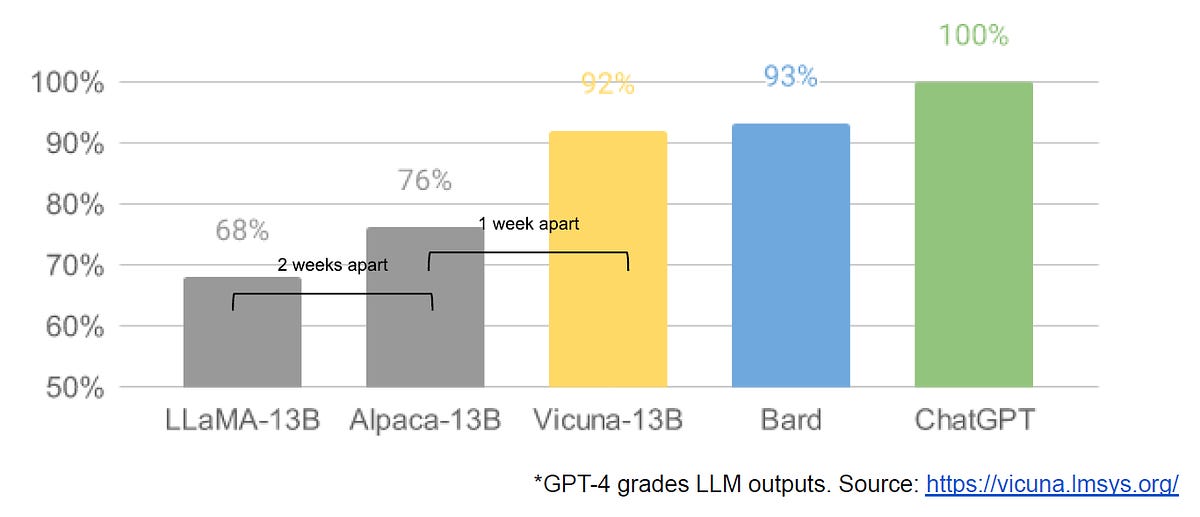
- Open-source models are faster, more customizable, more private, and pound-for-pound more capable. (View Highlight)
- We have no secret sauce. Our best hope is to learn from and collaborate with what others are doing outside Google (View Highlight)
- People will not pay for a restricted model when free, unrestricted alternatives are comparable in quality (View Highlight)
- Giant models are slowing us down. In the long run, the best models are the ones
which can be iterated upon quickly. We should make small variants more than an afterthought, now that we know what is possible in the <20B parameter regime (View Highlight)
- low-cost public involvement was enabled by a vastly cheaper mechanism for fine tuning called low rank adaptation, or LoRA, combined with a significant breakthrough in scale (latent diffusion for image synthesis, Chinchilla for LLMs (View Highlight)
- LoRA works by representing model updates as low-rank factorizations, which reduces the size of the update matrices by a factor of up to several thousand. This allows model fine-tuning at a fraction of the cost and time (View Highlight)
- Part of what makes LoRA so effective is that - like other forms of fine-tuning - it’s stackable. Improvements like instruction tuning can be applied and then leveraged as other contributors add on dialogue, or reasoning, or tool use (View Highlight)
- means that as new and better datasets and tasks become available, the model can be cheaply kept up to date, without ever having to pay the cost of a full run. (View Highlight)
- contrast, training giant models from scratch not only throws away the pretraining, but also any iterative improvements that have been made on top. In the open source world, it doesn’t take long before these improvements dominate, making a full retrain extremely costly (View Highlight)