Highlights §
- A good data scientist is focused solely on maximizing value for their organization, and thus is delicately balancing conducting new analyses, exploring new spaces, managing relationships with multiple product teams, and integrating new datasets. There just isn’t enough time in the day to do all that while also building good code (View Highlight)
 (View Highlight)
(View Highlight)- Add value, move quickly, build a good system — pick 2. And you have to Add Value (View Highlight)
- If they care about their job, adding value is not only a requirement, but also a reward-lever. Thus the trade-off is between “move quickly”, and “build a good system”. Problematically, as discussed above, the failure to build a good system will, over time, cause even the best data scientists/engineers to eventually slow down. (View Highlight)
- This forms a dilemma that is crucial to the understanding of how and why data teams need platforms to function effectively. We started this post by presenting this dilemma. We will then concretize properties of a “good” ML system, present a mental model to think about the trade-off, talk about how employing a platform mindset can make it less of a trade-off, and share how the open source platform we’re building at DAGWorks attempts to address these concerns. (View Highlight)
- While multiple professionals may disagree on this question, we will answer it in relation to the trade-off above. At a high level, a good system will not make you hate your colleague (or your previous self) when you work on it. OK, that’s nebulous. What do we mean, specifically? Note that these are not addressing the quality of the ML itself, only the quality of the code/infrastructure: (View Highlight)
- A good system does not break (often). While never breaking is aspirational (and, practically impossible), adequate fallbacks as well as a good story for testing changes make failure a tail risk, rather than a daily event. (View Highlight)
- A good system is easy to triage/debug. If you’re woken up in the middle of the night due to a broken ETL/web-service, you want to quickly figure out what part of the system is the cause/trigger. When you’ve identified the source, you need to be able to quickly fix it. (View Highlight)
- A good system is easy to understand. When you want to share what you’ve built with a colleague, determine the scope of a change you’re planning, or brush up on your knowledge of your code for analysis, you want to be able to quickly understand a system. While documentation is important, it is second to inherent readability, which requires simplicity and structure. (View Highlight)
- A good system is easy to modify. I may have a bridge to sell you if you genuinely believe that any code you write will be shipped to production, used, and never touched again. Not only will you have to routinely identify and fix bugs, iterate on the modeling techniques, and iron out assumptions that you (intentionally or unintentionally) made when building it, but you will also have to make larger changes. With any degree of success, you will likely be required to repurpose your system with new data sources, scale it to new use-cases, or even build a new system that shares elements of the current one. (View Highlight)
 (View Highlight)
(View Highlight)- (View Highlight)
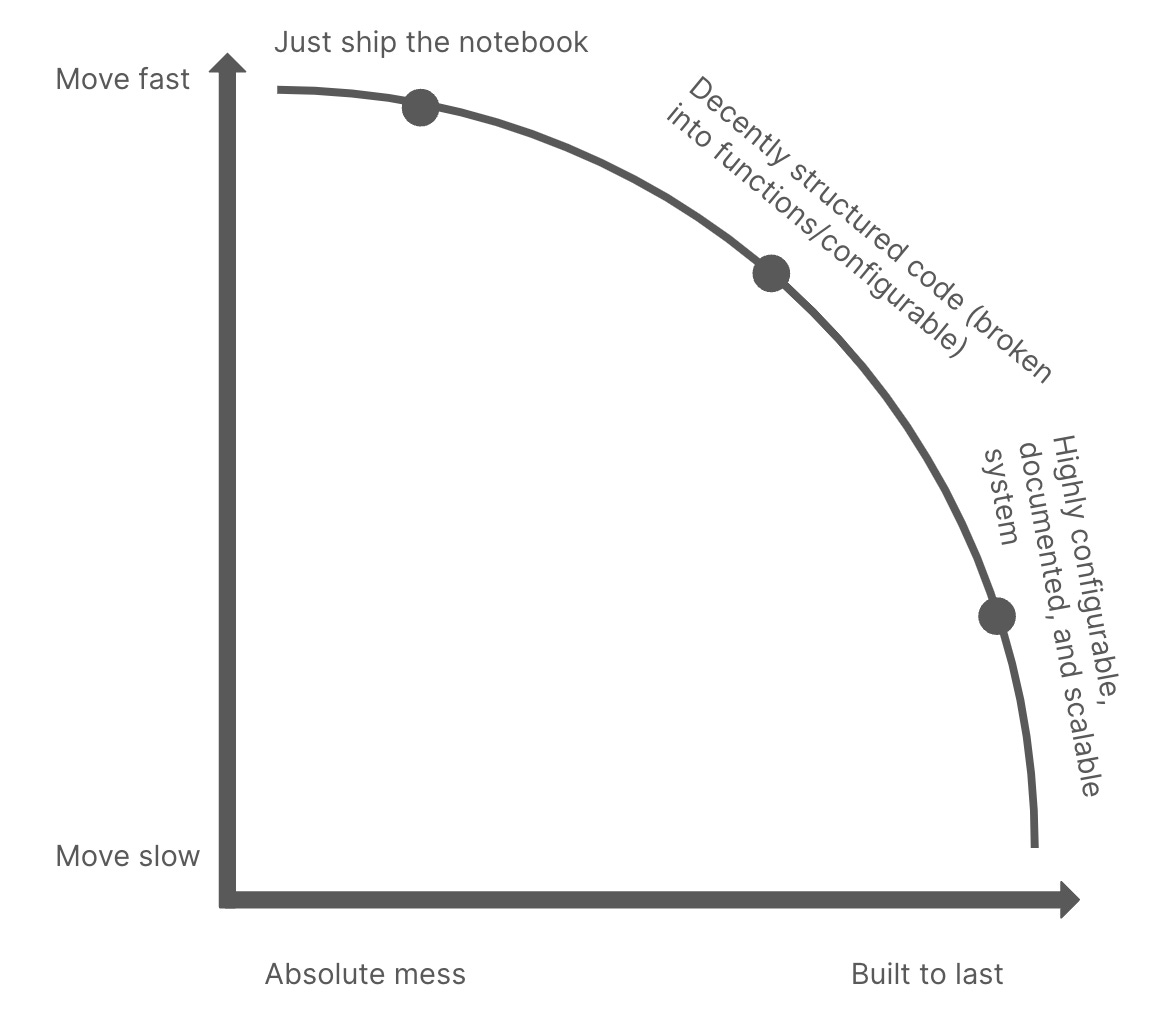
- So, as a first question when determining how to structure your code for production, you should ask yourself: Am I working along the efficient frontier? Another way of thinking about this is, for the required level of system quality, could I be moving any faster? And for the speed that I’m moving at, could I be building a better system? If the answer is yes, you could be moving faster, or yes, you could be building a better system, then you have no excuse. You should be moving faster.2 (View Highlight)
- Let us put on our platform team hat for a bit. While you may not have a team to build a platform for you, you will inevitably wear the platform engineer hat multiple times in your career, e.g. building tools for yourself and others. How do you approach doing this? A platform mindset is less opinionated about where you reside along the curve (within reason, that is), than (A) concerned about ensuring you have the information you need to build at any point along the efficient frontier (rather than within it) and (B) focused on improving the curve itself to allow for more optimal results that require less of a trade-off. (View Highlight)
- (A) in the image is largely the job of evangelizing technology and bringing yourself and others up to speed (documentation, presentation, and socialization are all critical skills – see our post on the ADKAR method for change management for a detailed guide). (B) in the image involves building new capabilities/toolsets, as well as understanding workflows/which tool sets to build. Also, note the shape of the new curve – it is intentionally less of a curve, and more of a right angle. This means that the trade-offs are less considerable. In a world with an ideal platform, building code to last requires far less of a sacrifice in speed-to-production, or perhaps none at all. (View Highlight)
- A good system does not break (often). As dataflows in Hamilton consist of python functions, it is easy to build unit tests for simple logic. Furthermore, it is easy to build integration tests for more complex logic/chains of functions. Mocking is done by data injection, rather than complex mocking libraries. (View Highlight)
- A good system is easy to triage/debug. Any error can be traced to an individual function, which is named according to its role in the final result. If data looks weird, Hamilton functions provide easy introspection on output data/dependencies, so you can trace the source of the data up the DAG scientifically. Hamilton also supports [runtime data quality checks](http://runtime data quality checks) that are extensible, so you can fail quickly if data assumptions are invalidated. In most other systems, figuring out why data is weird is a near-herculean task. (View Highlight)
- A good system is easy to understand. Hamilton provides multiple benefits here – functions are self-documenting so you can understand the inputs to any output variable simply by looking at the code. Furthermore, Hamilton has a sophisticated visualization capability that allows you to track lineage and understand execution plans. As more individuals in an organization adopt Hamilton, the effects of standardization naturally result in a network effect that makes each subsequent pipeline easier to read and manage. (View Highlight)
- A good system is easy to modify. Making and understanding changes is trivial. Changes in Hamilton are inherently targeted to specific functions, allowing you to isolate and test the desired effect. Furthermore, functions are naturally broken into modules, which encourage reuse and composition. (View Highlight)
- You might be wondering I like all these benefits, but don’t I have to learn a new system? And won’t that make me slower? Yes, you do have to learn a new system, but as we showed above, it’s just python functions! Furthermore, there’s a trick – you don’t always have to use Hamilton to its fullest extent. Hamilton supports multiple points along the efficient frontier between good code and quick development, and makes it easier to move along that curve. Let’s make this more concrete by looking at some different goals for getting data projects to production: (View Highlight)