
Highlights §
- In this blog we explain most valuable evaluation plots to assess the business value of a predictive model. Since these visualisations are not included in most popular model building packages or modules in R and Python, we show how you can easily create these plots for your own predictive models with our modelplotr r package and our modelplotpy python module (Prefer python? Read all about modelplotpy here!). This will help you to explain your model’s business value in laymans terms to non-techies. (View Highlight)
- If your fellow business colleagues didn’t already wander away during your presentation about your fantastic predictive model, it will definitely push them over the edge when you start talking like this. Why? Because the ROC curve is not easy to quickly explain and also difficult to translate into answers on the business questions your spectators have. And these business questions were the reason you’ve built a model in the first place! (View Highlight)
- What business questions? We build models for all kinds of supervised classification problems. Such as predictive models to select the best records in a dataset, which can be customers, leads, items, events… For instance: You want to know which of your active customers have the highest probability to churn; you need to select those prospects that are most likely to respond to an offer; you have to identify transactions that have a high risk to be fraudulent. During your presentation, your audience is therefore mainly focused on answering questions like Does your model enable us to our target audience? How much better are we, using your model? What will the expected response on our campaign be? What is the financial impact of using your model? (View Highlight)
- During our model building efforts, we should already be focused on verifying how well the model performs. Often, we do so by training the model parameters on a selection or subset of records and test the performance on a holdout set or external validation set. We look at a set of performance measures like the ROC curve and the AUC value. These plots and statistics are very helpful to check during model building and optimization whether your model is under- or overfitting and what set of parameters performs best on test data. However, these statistics are not that valuable in assessing the business value the model you developed. (View Highlight)
- One reason that the ROC curve is not that useful in explaining the business value of your model, is because it’s quite hard to explain the interpretation of ‘area under the curve’, ‘specificity’ or ‘sensitivity’ to business people. Another important reason that these statistics and plots are useless in your business meetings is that they don’t help in determining how to apply your predictive model: What percentage of records should we select based on the model? Should we select only the best 10% of cases? Or should we stop at 30%? Or go on until we have selected 70%?… This is something you want to decide together with your business colleague to best match the business plans and campaign targets they have to meet. The four plots - the cumulative gains, cumulative lift, response and cumulative response - and three financial plots - costs & revenues, profit and return on investment - we are about to introduce are in our view the best ones for that cause. (View Highlight)
- Before we throw more code and output at you, let’s get you familiar with the plots we so strongly advocate to use to assess a predictive model’s business value. Although each plot sheds light on the business value of your model from a different angle, they all use the same data:
• Predicted probability for the target class
• Equally sized groups based on this predicted probability, named ntiles
• Actual number of observed target class observations in these groups (ntiles)
Regarding the ntiles: It’s common practice to split the data to score into 10 equally large groups and call these groups deciles. Observations that belong to the top-10% with highest model probability in a set, are in decile 1 of that set; the next group of 10% with high model probability are decile 2 and finally the 10% observations with the lowest model probability on the target class belong to decile 10.
*Notice that modelplotr does (View Highlight)
- Each of the plots in modelplotr places the ntiles on the x axis and another measure on the y axis. The ntiles are plotted from left to right so the observations with the highest model probability are on the left side of the plot. This results in plots like this:
 (View Highlight)
(View Highlight)
- When we apply the model and select the best X ntiles, what % of the actual target class observations can we expect to target?
Hence, the cumulative gains plot visualises the percentage of the target class members you have selected if you would decide to select up until ntile X. This is a very important business question, because in most cases, you want to use a predictive model to target a subset of observations - customers, prospects, cases,… - instead of targeting all cases. And since we won’t build perfect models all the time, we will miss some potential. And that’s perfectly all right, because if we are not willing to accept that, we should not use a model in the first place. Or build only perfect models, that scores all actual target class members with a 100% probability and all the cases that do not belong to the target class with a 0% probability. However, if you’re such a wizard, you don’t need these plots any way or you should have a careful look at your model - maybe you’re cheating?… (View Highlight)
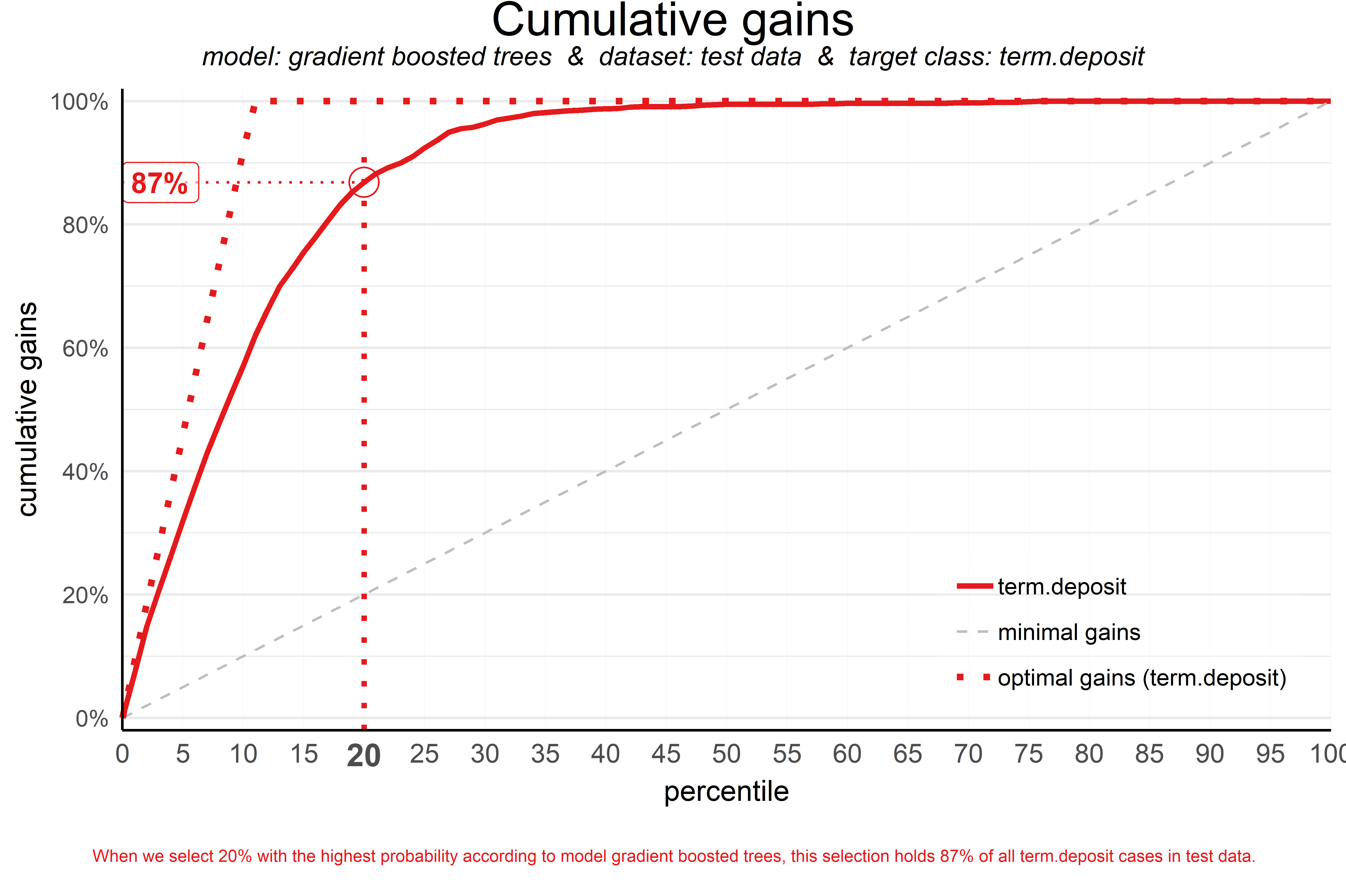
- So, we’ll have to accept we will lose some. What percentage of the actual target class members you do select with your model at a given ntile, that’s what the cumulative gains plot tells you. The plot comes with two reference lines to tell you how good/bad your model is doing: The random model line and the wizard model line. The random model line tells you what proportion of the actual target class you would expect to select when no model is used at all. This vertical line runs from the origin (with 0% of cases, you can only have 0% of the actual target class members) to the upper right corner (with 100% of the cases, you have 100% of the target class members). It’s the rock bottom of how your model can perform; are you close to this, then your model is not much better than a coin flip. The wizard model is the upper bound of what your model can do. It starts in the origin and rises as steep as possible towards 100%. Say, exactly 10% of all cases belong to the target category. This means that this line goes steep up from the origin to the value of decile 1 (or percentile 10 in case ntiles=100) and cumulative gains of 100% and remains there for all other ntiles as it is a cumulative measure. Your model will always move between these two reference lines - closer to a wizard is always better - and looks like this: (View Highlight)
 plot of chunk gainsplotannotated (View Highlight)
plot of chunk gainsplotannotated (View Highlight)- Our highlight_ntile parameter adds some guiding elements to the plot at ntile 20 as well as a text box below the graph with the interpretation of the plot at ntile 20 in words. This interpretation is also printed to the console. Our simple model - only 6 pedictors were used - seems to do a nice job selecting the customers interested in buying term deposites. When we select 20% with the highest probability according to gradient boosted trees, this selection holds 87% of all term deposit cases in test data. With a perfect model, we would have selected 100%, since less than 20% of all customers in the test set buy term deposits. A random pick would only hold 20% of the customers with term deposits. How much better than random do we do? This brings us to plot number two! (View Highlight)
- The cumulative lift plot, often referred to as lift plot or index plot, helps you answer the question:
When we apply the model and select the best X ntiles, how many times better is that than using no model at all?
The lift plot helps you in explaining how much better selecting based on your model is compared to taking random selections instead. Especially when models are not yet used that often within your organisation or domain, this really helps business understand what selecting based on models can do for them. (View Highlight)
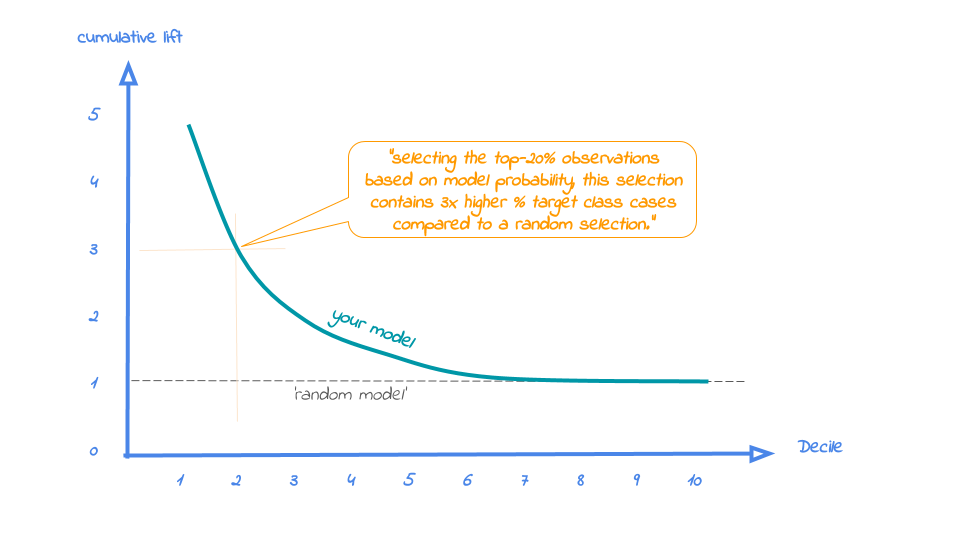
- The lift plot only has one reference line: the ‘random model’. With a random model we mean that each observation gets a random number and all cases are devided into ntiles based on these random numbers. When we would do that, the % of actual target category observations in each ntile would be equal to the overall % of actual target category observations in the total set. Since the lift is calculated as the ratio of these two numbers, we get a horizontal line at the value of 1. Your model should however be able to do better, resulting in a high ratio for ntile 1. How high the lift can get, depends on the quality of your model, but also on the % of target class observations in the data: If 50% of your data belongs to the target class of interest, a perfect model would ‘only’ do twice as good (lift: 2) as a random selection. With a smaller target class value, say 10%, the model can potentially be 10 times better (lift: 10) than a random selection. Therefore, no general guideline of a ‘good’ lift can be specified. Towards the last ntile, since the plot is cumulative, with 100% of cases, we have the whole set again and therefore the cumulative lift will always end up at a value of 1. It looks like this: (View Highlight)
 (View Highlight)
(View Highlight)- (View Highlight)
- A term deposit campaign targeted at a selection of 20% of all customers based on our gradient boosted trees model can be expected to have a 4 times higher response (434%) compared to a random sample of customers. Not bad, right? The cumulative lift really helps in getting a positive return on marketing investments. It should be noted, though, that since the cumulative lift plot is relative, it doesn’t tell us how high the actual reponse will be on our campaign… (View Highlight)
- One of the easiest to explain evaluation plots is the response plot. It simply plots the percentage of target class observations per ntile. It can be used to answer the following business question:
When we apply the model and select ntile X, what is the expected % of target class observations in that ntile?
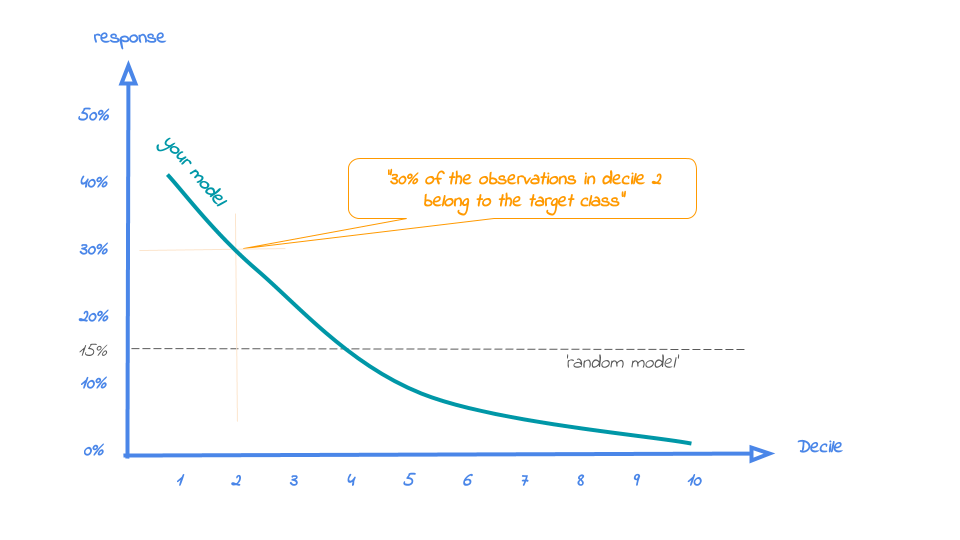
The plot has one reference line: The % of target class cases in the total set. It looks like this: (View Highlight)
 (View Highlight)
(View Highlight)- (View Highlight)
- A good model starts with a high response value in the first ntile(s) and suddenly drops quickly towards 0 for later ntiles. This indicates good differentiation between target class members - getting high model scores - and all other cases. An interesting point in the plot is the location where your model’s line intersects the random model line. From that ntile onwards, the % of target class cases is lower than a random selection of cases would hold. (View Highlight)
- As the plot shows and the text below the plot states: When we select decile 1 according to model gradient boosted trees in dataset test data the % of term deposit cases in the selection is 51%.. This is quite good, especially when compared to the overall likelihood of 12%. The response in the 20th ntile is much lower, about 10%. From ntile 22 onwards, the expected response is lower than the overall likelihood of 12%. However, most of the time, our model will be used to select the highest decile up until some decile. That makes it even more relevant to have a look at the cumulative version of the response plot. And guess what, that’s our final plot! (View Highlight)
- When we apply the model and select up until ntile X, what is the expected % of target class observations in the selection?
The reference line in this plot is the same as in the response plot: the % of target class cases in the total set.
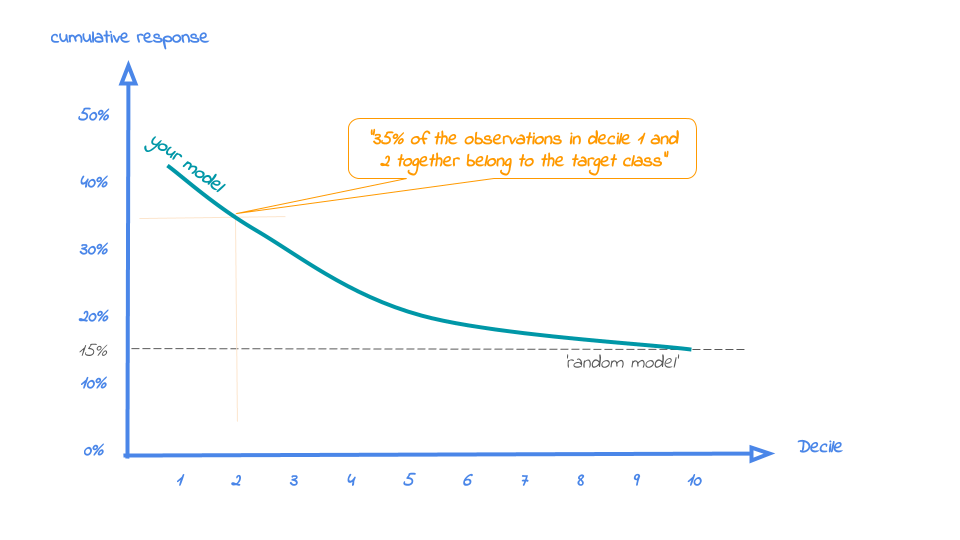 Whereas the response plot crosses the reference line, in the cumulative response plot it never crosses it but ends up at the same point for the last ntile: Selecting all cases up until ntile 100 is the same as selecting all cases, hence the % of target class cases will be exactly the same. This plot is most often used to decide - together with business colleagues - up until what decile to select for a campaign. (View Highlight)
Whereas the response plot crosses the reference line, in the cumulative response plot it never crosses it but ends up at the same point for the last ntile: Selecting all cases up until ntile 100 is the same as selecting all cases, hence the % of target class cases will be exactly the same. This plot is most often used to decide - together with business colleagues - up until what decile to select for a campaign. (View Highlight)
- When we select ntiles 1 until 30 according to model gradient boosted trees in dataset test data the % of term deposit cases in the selection is 36%. Since the test data is an independent set, not used to train the model, we can expect the response on the term deposit campaign to be 36%. (View Highlight)
- The cumulative response percentage at a given decile is a number your business colleagues can really work with: Is that response big enough to have a successfull campaign, given costs and other expectations? Will the absolute number of sold term deposits meet the targets? Or do we lose too much of all potential term deposit buyers by only selecting the top 30%? To answer that question, we can go back to the cumulative gains plot. And that’s why there’s no absolute winner among these plots and we advice to use them all. To make that happen, there’s also a function to easily combine all four plots. (View Highlight)
- And there’s more! To plot the financial implications of implementing a predictive model, modelplotr provides three additional plots: the Costs & revenues plot, the Profit plot and the ROI plot. So, when you know what the fixed costs, variable costs and revenues per sale associated with a campaign based on your model are, you can use these to visualize financial consequences of using your model. Here, we’ll just show the Profit plot. See the package vignette for more details on the Costs & Revenues plot and the Return on Investment plot. (View Highlight)
- Business colleagues should be able to tell you the expected costs and revenues regarding the campaign. Let’s assume they told us fixed costs for the campaign (a tv commercial and some glossy print material) are in total € 75,000 and each targeted customer costs another € 50 (prospects are called and receive an incentive) and the expected revenue per new term deposit customer is € 250 according to the business case. (View Highlight)
- Using this plot, we can decide to select the top 19 ntiles according to our model to maximize profit and earn about € 94,000 with this campaign. Both decreasing and increasing the selection based on the model would harm profits, as the plot clearly shows. (View Highlight)