Stanford Alpaca, and the Acceleration of on-Device Large Language Model Development §
Highlights §
- We introduce Alpaca 7B, a model fine-tuned from the LLaMA 7B model on 52K instruction-following demonstrations. Alpaca behaves similarly to OpenAI’s text-davinci-003, while being surprisingly small and easy/cheap to reproduce (<600$) (View Highlight)
- One of the great innovations from OpenAI was their application of instruction tuning to GPT-3: (View Highlight)
- On prompts submitted by our customers to the API, our labelers provide demonstrations of the desired model behavior, and rank several outputs from our models. We then use this data to fine-tune GPT-3. (View Highlight)
- Prior to this, you had to think very carefully about how to construct your prompts. Thanks to instruction tuning you can be a lot more, well, human in the way you interact with the model. (View Highlight)
- Keep in mind these models are not finetuned for question answering. As such, they should be prompted so that the expected answer is the natural continuation of the prompt. (View Highlight)
- Thanks to the team at Stanford we now have an answer: 52,000 training samples and $100 of training compute! From their blog post: (View Highlight)
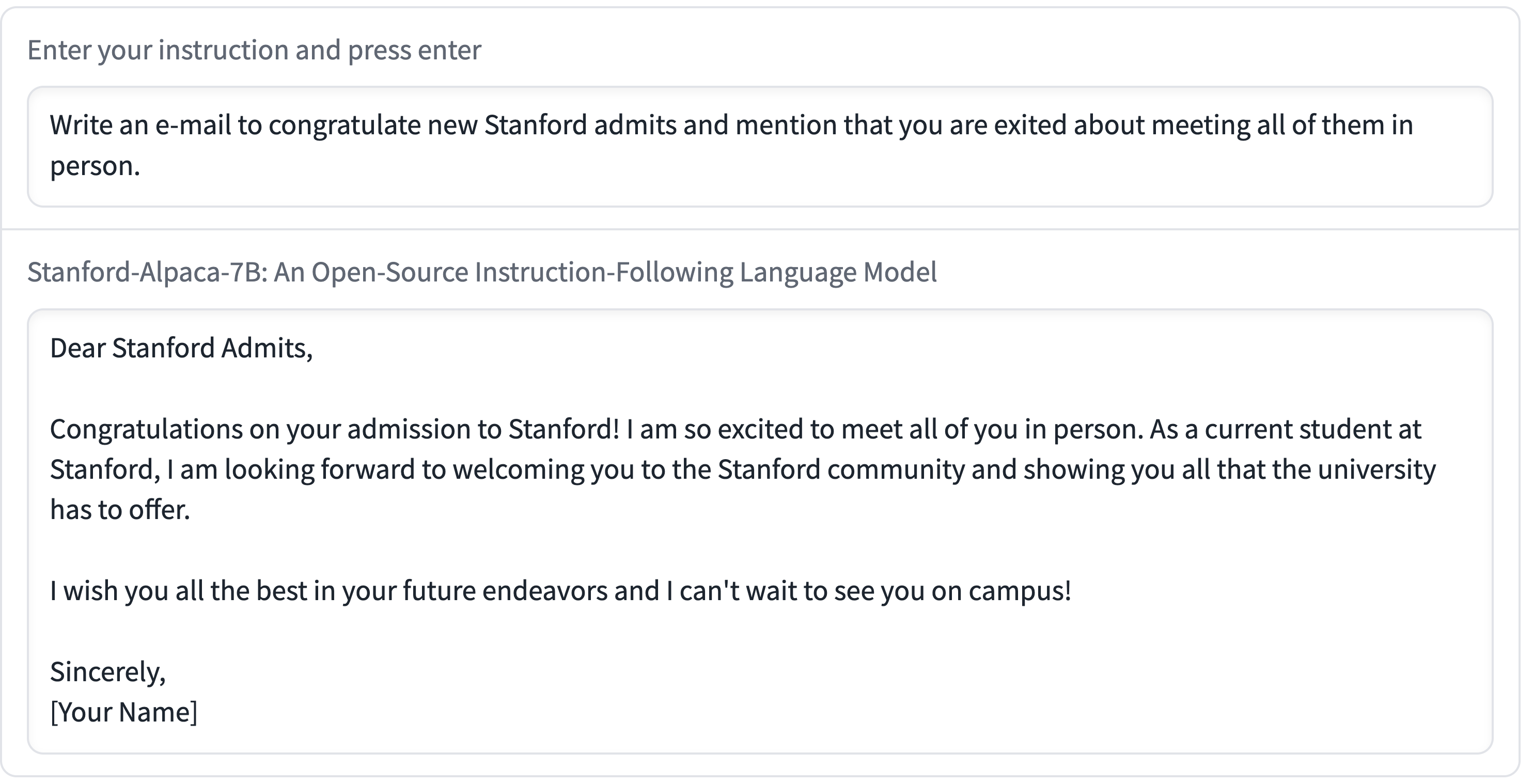
- Something that stuns me about Alpaca is the quality they claim to be able to get from the 7B model—the smallest of the LLaMA models, and the one which has been seen running (albeit glacially slowly) on a RaspberryPi and a mobile phone! Here’s one example from their announcement: (View Highlight)
- We emphasize that Alpaca is intended only for academic research and any commercial use is prohibited. There are three factors in this decision: First, Alpaca is based on LLaMA, which has a non-commercial license, so we necessarily inherit this decision. Second, the instruction data is based OpenAI’s text-davinci-003, whose terms of use prohibit developing models that compete with OpenAI. Finally, we have not designed adequate safety measures, so Alpaca is not ready to be deployed for general use. (View Highlight)
- On Saturday 11th March I wrote about how Large language models are having their Stable Diffusion moment. Today is Monday. Let’s look at what’s happened in the past three days. (View Highlight)
- Note: In the past three days since the release of an article about the increasing relevance of large language models, the development of on-device language models has been rapidly accelerating, with Stanford Alpaca being the most recent development. Stanford Alpaca is a toolkit designed to help developers and machine learning practitioners develop and deploy large language models on mobile and other edge devices.
- Those 52,000 samples they used to fine-tune the model? Those were the result of a prompt they ran against GPT-3 itself! Here’s the prompt they used: (View Highlight)
- Then they include three random example instructions from a list of 175 they had prepared by hand. The completed prompt sent to OpenAI would include the above instructions followed by something like this (View Highlight)
- They spent $500 on OpenAI credits to assemble the 52,000 examples they used to fine-tune their model. (View Highlight)
- There’s a related concept to this called Model Extraction, where people build new models that emulate the behaviour of others by firing large numbers of examples through the other model and training a new one based on the results. (View Highlight)