
Highlights §
- Transformers are a class of deep learning models that are defined by some architectural traits. They were first introduced in the now famous Attention is All you Need paper by Google researchers in 2017 (the paper has accumulated a whooping 38k citations in only 5 years) and associated blog post. (View Highlight)
- The Transformer architecture is a specific instance of the encoder-decoder models that had become popular just over the 2–3 years prior. Up until that point however, attention was just one of the mechanisms used by these models, which were mostly based on LSTM (Long Short Term Memory) and other RNN (Recurrent Neural Networks) variations. The key insight of the Transformers paper was that, as the title implies, attention could be used as the only mechanism to derive dependencies between input and output. (View Highlight)
 (View Highlight)
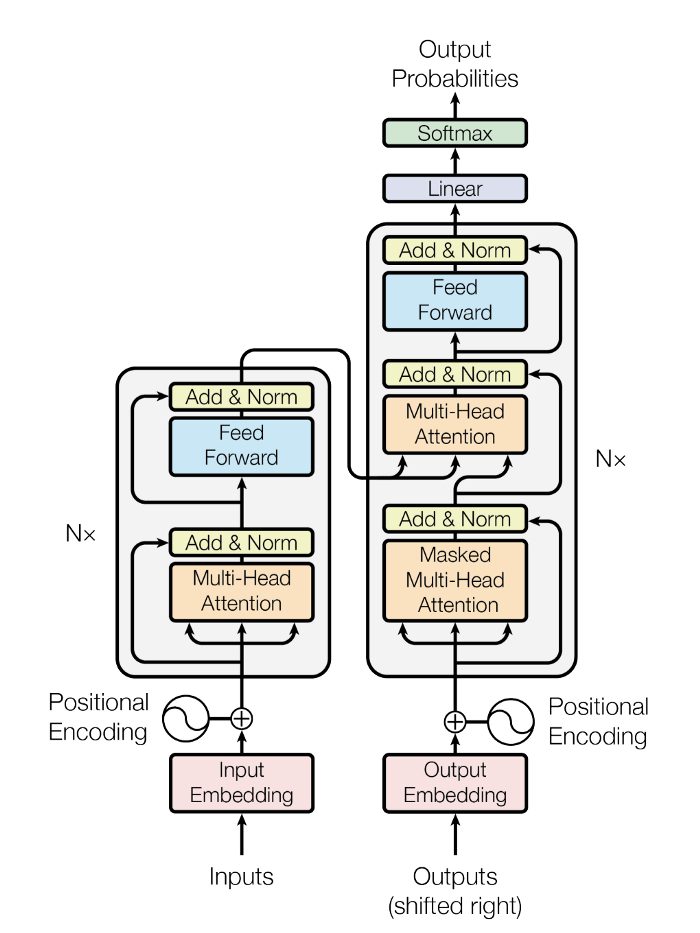
(View Highlight)- A generic encoder/decoder architecture is made up of two models. The encoder takes the input and encodes it into a fixed-length vector. The decoder takes that vector and decodes it into the output sequence. The encoder and decoder are jointly trained to minimize the conditional log-likelihood. Once trained the encoder/decoder can generate an output given an input sequence or can score a pair of input/output sequences. (View Highlight)
- n the case of the original Transformer architecture, both encoder and decoder had 6 identical layers. In each of those 6 layers the Encoder has two sub layers: a multi-head attention layer, and a simple feed forward network. Each sublayer has a residual connection and a layer normalization. The output size of the Encoder is 512. The Decoder adds a third sublayer, which is another multi-head attention layer over the output of the Encoder. Besides, the other multi-head layer in the decoder is masked to prevent attention to subsequent positions. (View Highlight)
- t is clear from the description above that the only “exotic” elements of the model architecture are the multi-headed attention, but, as described above, that is where the whole power of the model lies (View Highlight)
- An attention function is a mapping between a query and a set of key-value pairs to an output. (View Highlight)
- Transformers use multi-headed attention, which is a parallel computation of a specific attention function called scaled dot-product attention. (View Highlight)