Highlights §
- LoRA (Low-Rank Adaptation) is a new technique for fine tuning large scale pre-trained models. Such models are usually trained on general domain data, so as to have the maximum amount of data. (View Highlight)
- It’s possible to fine-tune a model just by initializing the model with the pre-trained weights and further training on the domain specific data. With the increasing size of pre-trained models, a full forward and backward cycle requires a large amount of computing resources. Fine tuning by simply continuing training also requires a full copy of all parameters for each task/domain that the model is adapted to. (View Highlight)
- We learn the parameters ΔΘΔΘ\Delta \Theta with dimension |ΔΘ||ΔΘ||\Delta \Theta| equals to |Θ0||Θ0||\Theta_0|. When |Θ0||Θ0||\Theta_0| is very large, such as in large scale pre-trained models, finding ΔΘΔΘ\Delta \Theta becomes computationally challenging. Also, for each task you need to learn a new ΔΘΔΘ\Delta \Theta parameter set, making it even more challenging to deploy fine-tuned models if you have more than a few specific tasks. (View Highlight)
- The observation is that neural nets have many dense layers performing matrix multiplication, and while they typically have full-rank during pre-training, when adapting to a specific task the weight updates will have a low “intrinsic dimension”. (View Highlight)
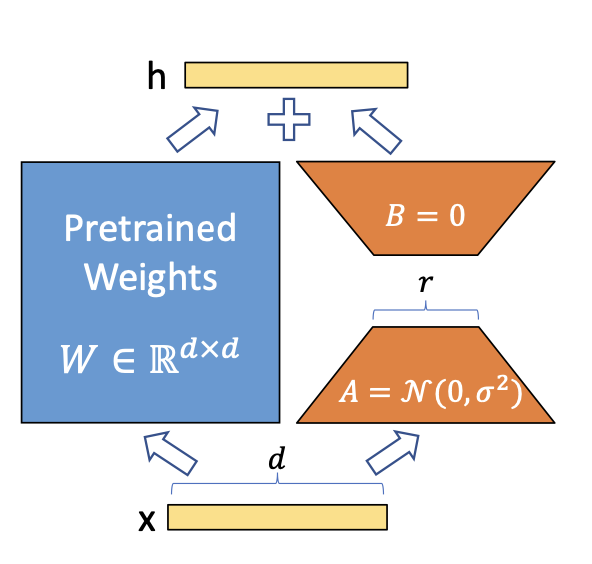
- A simple matrix decomposition is applied for each weight matrix update Δθ∈ΔΘΔθ∈ΔΘ\Delta \theta \in \Delta \Theta. Considering Δθi∈ℝd×kΔθi∈Rd×k\Delta \theta_i \in \mathbb{R}^{d \times k} the update for the iiith weight in the network, LoRA approximates it with:
Δθi≈Δϕi=BAΔθi≈Δϕi=BA
\Delta \theta_i \approx \Delta \phi_i = BA (View Highlight)
- Thus instead of learning d×kd×kd \times k parameters we now need to learn (d+k)×r(d+k)×r(d + k) \times r which is easily a lot smaller given the multiplicative aspect. (View Highlight)
- LoRA does not increase inference latency, as once fine tuning is done, you can simply update the weights in ΘΘ\Theta by adding their respective Δθ≈ΔϕΔθ≈Δϕ\Delta \theta \approx \Delta \phi. It also makes it simpler to deploy multiple task specific models on top of one large model, as |ΔΦ||ΔΦ||\Delta \Phi| is much smaller than |ΔΘ||ΔΘ||\Delta \Theta|. (View Highlight)
- Turns out that Transformers models are mostly clever organization of these matrix multiplications, and applying LoRA only to these layers is enough for reducing the fine tuning cost by a large amount while still getting good performance. You can see the experiments in the LoRA paper.
Of course, the idea of LoRA is simple enough that it can be applied not only to linear layers. You can apply it to convolutions, embedding layers and actually any other layer. (View Highlight)