What is a Vector Database? §

Highlights §
- Being able to search across images, video, text, audio, and other forms of unstructured data via their content rather than human-generated labels or tags is exactly what vector databases were meant to solve. (View Highlight)
- a vector database is a fully managed, no-frills solution for storing, indexing, and searching across a massive dataset of unstructured data that leverages the power of embeddings from machine learning models. (View Highlight)
- An increasing number of traditional relational databases, and search systems such as Clickhouse and Elasticsearch are including built-in vector search plugins. Elasticsearch 8.0, for example, includes vector insertion and ANN search functionality that can be called via restful API endpoints. The problem with vector search plugins should be clear as night and day - these solutions do not take a full-stack approach to embedding management and vector search. Instead, these plugins are meant to be enhancements on top of existing architectures, thereby making them limited and unoptimized. Developing an unstructured data application atop a traditional database would be like trying to fit lithium batteries and electric motors inside a the frame of a gas-powered car - not a great idea! (View Highlight)
- a vector database should have the following features: 1) scalability and tunability, 2) multi-tenancy and data isolation, 3) a complete suite of APIs, and 4) an intuitive user interface/administrative console. (View Highlight)
- projects such as FAISS, ScaNN, and HNSW are lightweight ANN libraries rather than managed solutions. The intention of these libraries is to aid in the construction of vector indices - data structures designed to significantly speed up nearest neighbor search for multi-dimensional vectors[1]. If your dataset is small and limited, these libraries can prove to be sufficient for unstructured data processing, even for systems running in production. However, as dataset sizes increase and more users are onboarded, the problem of scale becomes increasingly difficult to solve. (View Highlight)
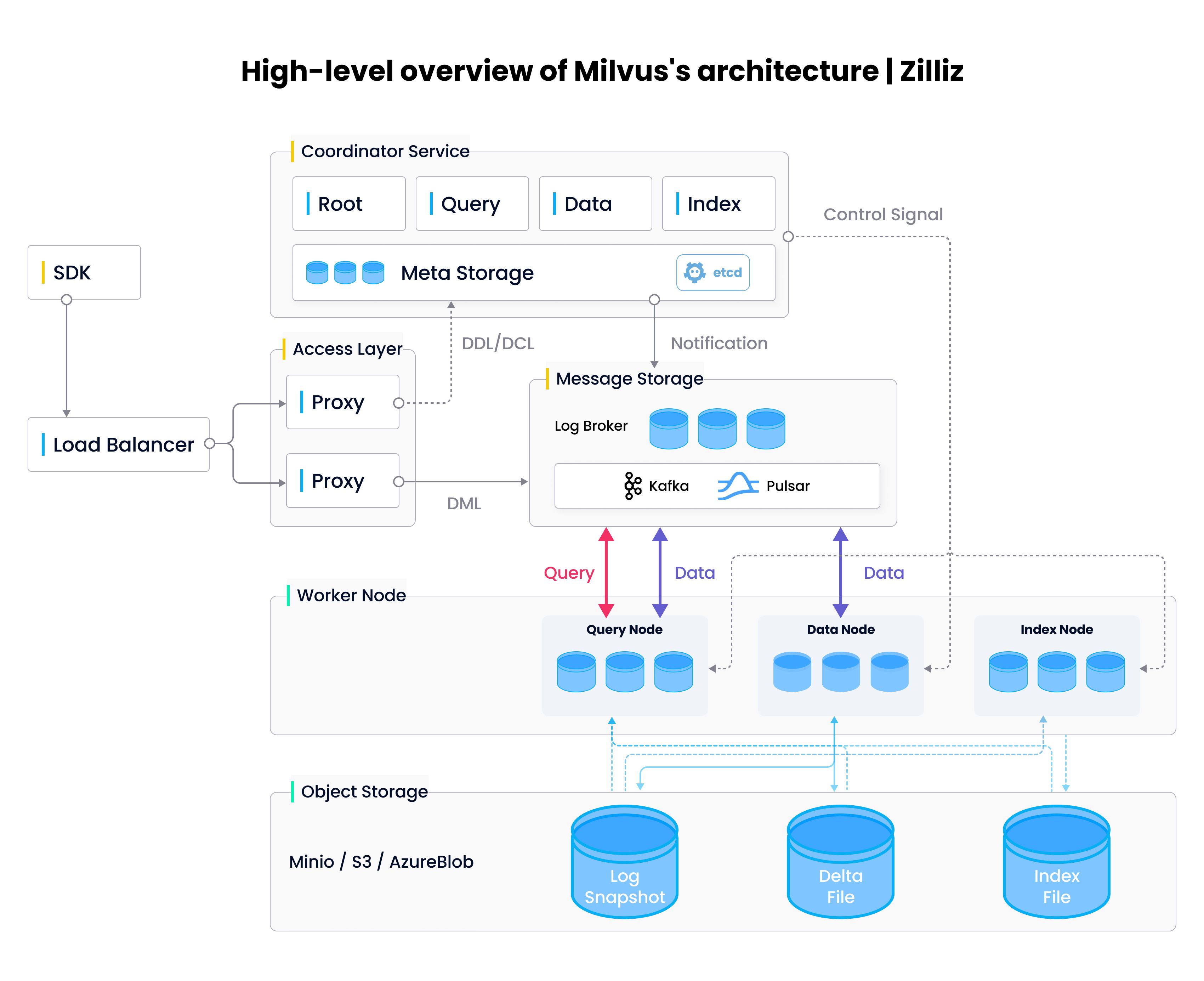 (View Highlight)
(View Highlight)- Vector databases also operate in a totally different layer of abstraction from vector search libraries - vector databases are full-fledged services, while ANN libraries are meant to be integrated into the application that you’re developing. In this sense, ANN libraries are one of the many components that vector databases are built on top of, similar to how Elasticsearch is built on top of Apache Lucene. (View Highlight)
- An increasing number of traditional databases and search systems such as Clickhouse and Elasticsearch are including built-in vector search plugins. Elasticsearch 8.0, for example, includes vector insertion and ANN search functionality that can be called via restful API endpoints. The problem with vector search plugins should be clear as night and day - these solutions do not take a full-stack approach to embedding management and vector search. Instead, these plugins are meant to be enhancements on top of existing architectures, thereby making them limited and unoptimized. (View Highlight)
- ikewise, vector databases are composed of a number of evolving software components. Roughly speaking, these can be broken down into the storage, the index, and the service. Although these three components are tightly integrated[2], companies such as Snowflake have shown the broader storage industry that “shared nothing” database architectures are arguably superior to the traditional “shared storage” cloud database models. Thus, the first technical challenge associated with vector databases is designing a flexible and scalable data model. (View Highlight)
- With data already stored in a vector database, being able to search across that data, i.e. querying and indexing, is the next important component. The compute-heavy nature of machine learning and multi-layer neural networks has allowed GPUs, NPUs/TPUs, FPGAs, and other general purpose compute hardware to flourish. Vector indexing and querying is also compute-heavy, operating at maximum speed and efficiency when run on accelerators. This diverse set of compute resources gives way to the second main technical challenge, developing a heterogeneous computing architecture. (View Highlight)
- While both Elasticsearch and Milvus have methods for creating indexes, inserting embedding vectors, and performing nearest neighbor search, it’s clear from these examples that Milvus has a more intuitive vector search API (better user-facing API) and broader vector index + distance metric support (better tunability). Milvus also plans to support more vector indices and allow for querying via SQL-like statements in the future, further improving both tunability and usability. (View Highlight)
- he last step is making sure your application can, well, read from the database - this ties closely into the API and user interface bullet points mentioned in the first section. While a new category of database necessitates a new architecture in order to extract maximal performance at minimal cost, the majority of vector database users are still acclimated to traditional CRUD operations (e.g.
INSERT, SELECT, UPDATE, and DELETE in SQL). Therefore, the final primary challenge is developing a set of APIs and GUIs that leverage existing user interface conventions while maintaining compatibility with the underlying architecture. (View Highlight)
- • High-dimensional search: Vector databases can efficiently perform similarity searches on high-dimensional vectors, commonly used in machine learning and AI applications, such as image recognition, natural language processing, and recommendation systems.
• Scalability: Vector databases can scale horizontally, efficiently storing and retrieving large amounts of vector data. Scalability is significant for applications that require real-time search and retrieval of large amounts of data.
• Flexibility: Vector databases can handle various vector data types, including sparse and dense vectors. They can also handle multiple data types, including numerical, text, and binary.
• Performance: Vector databases perform similarity searches efficiently, often providing faster search times than traditional databases.
• Customizable indexing: Vector databases allow custom indexing schemes for specific use cases and data types. (View Highlight)